| MOSCOW STATE UNIVERSITY, INSTITUTE OF NUCLEAR PHYSICS | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
CENTRE FOR PHOTONUCLEAR EXPERIMENTS DATA Online Services | Partners | About | Team | Publications | Contacts | |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
CDFE: Online Services
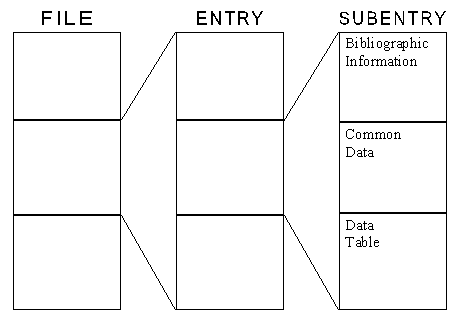
EXFOR Records EXFOR Exchange files consist of 80 character ASCII records. The format of columns 1-66 varies according to the record type as outlined in the following chapters. Columns 67-79 is used to uniquely identify a record within the file. The records on the file are in ascending order according to the record identification. Column 80 is reserved for an alteration flag. Record identification. The record identification is divided into three fields: the accession number (entry), subaccession number (subentry), and record number within the subentry. The format of these fields is as follows.
Alteration flag (column 80). The last column of each record contains the alteration flag which is used to indicate that a record and/or following records has been altered (i.e., added, deleted or modified) since the work was last transmitted. The flag field will normally contain a blank to indicate an unaltered record. System Identifiers Each of the sections of an EXFOR file begins and ends with a system identifier. Each of the following system identifiers indicates the beginning of one of these sections.
The following system identifiers are defined.
POINTERSDifferent pieces of EXFOR information may be linked together by pointers. A pointer is a numeric or alphabetic character (1,2...9,A,B,...Z) placed in the eleventh column of the information-identifier keyword field in the BIB section and in the field headings in the COMMON or DATA section. Pointers may link, for example,
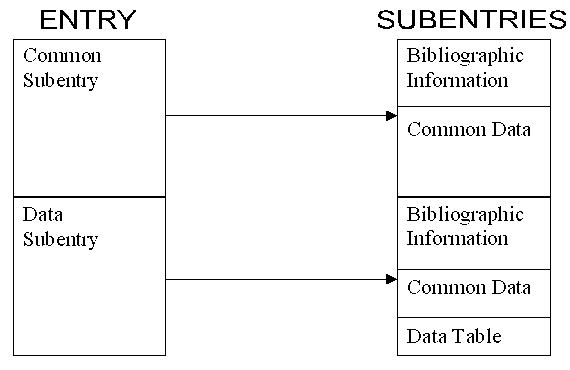
In general, a pointer is valid for only one subentry. A pointer used in the first subentry applies to all subentries and has a unique meaning throughout the entire entry. BIB SECTIONThe BIB section contains the bibliographic information (e.g., reference, authors), descriptive information (e.g., neutron source, method, facility), and administrative information (e.g., history) associated with the data presented. It is identified on an exchange file as that information between the system identifiers BIB and ENDBIB. A BIB record consists of three parts:
BIB information for a given data set consists of the information contained in the BIB section of its subentry together with the BIB information in subentry 001. That is, information coded in subentry 001 applies to all other subentries in the same entry. A specific information-identifier keyword may be included in either subentry or both. Information-identifier keywords The information-identifier keyword is used to define the significance of the information given in columns 12-66. The keyword is left adjusted to begin in column 1, and does not exceed a length of 10 characters (column 11 is either blank, or contains a pointer, see Chapter 5). These keywords may, in general, appear in any order within the BIB section, however, an information-identifier keyword is not repeated within any one BIB section. If pointers are present, they appear on the first record of the information to which they are attached and are not repeated on continuation records. A pointer is assumed to refer to all BIB information until either another pointer or a new keyword is encountered. As this implies, pointer-independent information for each keyword appears first. Coded (machine-retrievable) information Coded information may be used:
Coded information is enclosed in parentheses and left adjusted so that the opening parenthesis appears in column 12. Several pieces of coded information may be associated with a given information-identifier keyword. Codes for use with a specific keyword are found in the relevant dictionary. However, for some keywords, the code string may include retrievable information other than a code from one of the dictionaries. In general, codes given in the dictionaries may be used singly or in conjunction with one or more codes from the same dictionary. Two options exist if more than one code is used:
For some cases, the information may be continued onto successive records. Information on continuation records does not begin before column 12 (columns 1-10 are blank and column 11 is blank or contains a pointer). Note that some information-identifier keywords have no coded information associated with them and that, for many keywords which may have coded information associated with them, it need not always be present. Free text Free text may be entered in columns 12-66 under each of the information-identifier keywords in the BIB section. The text follows any coded information on the record or may begin on a separate record; it may be continued onto any number of records. The language of the free text is English. Coding of nuclides and compounds. Nuclides appear in the coding of many keywords. The general code format is Z-S-A-X, where:
Compounds may in some cases replace the nuclide code. The general format for coding compounds is either the specific compound code, taken from Dictionary 9, or the general code for a compound of the form Z-S-CMP. Example: 26-FE-CMP COMMON AND DATA SECTIONSA data table is, generally, a function of one or more independent variables, e.g.,
When more than one representation of Y is present, the table may be X vs. Y and Y', with associated errors for X, Y and Y' (e.g., X = energy, Y = absolute cross section, Y' = relative cross section), and possible associated information. The criteria for grouping Y with Y' are that they both be derived from the same experimental information by the author of the data. For some data, the data table does not have an independent variable X but only a function Y. (Examples: Spontaneous ν resonance energies without resonance parameters) Additional variables may be associated with the data, e.g., errors, standards. The format of the common data (COMMON) and data table (DATA) sections is identical. Each section is a table of data containing the data headings and units associated with each field. The difference between the common data and data table is:
Each physical record may contain up to six information fields, each 11 columns wide. If more than six fields are used, the remaining information is contained on the following records. Therefore, a data line consists of up to three physical records. The number of fields in a data line is restricted to 18. Records are not packed; rather, individual point information is kept on individual records; i.e., if only four fields are associated with a data line, the remaining two fields are left blank, and, in the case of the data table, the information for the next line begins on the following record. These rules also apply to the headings and units associated with each field. The content of the COMMON and DATA sections are as follows:
The values are either zero or have absolute values between 1.0000E-38 and 9.999E+38. COMMON Section The COMMON section is identified as that information between the system identifiers COMMON and ENDCOMMON. In the common data table, only one value is entered for a given field, and successive fields are not integrally associated with one another. An example of a common data table with more than 6 fields:
DATA Section The DATA section is identified as that information between the system identifiers DATA and ENDDATA. In the DATA table, all entries on a record are integrally associated with an individual point. Independent variables precede dependent variables, and are monotonic until the value of the preceding independent variable, if any exist, changes. Every line in a data table gives data information. This means, for example, that a blank in a field headed DATA is permitted only when another field contains the data information on the same line, e.g., under DATA-MAX. In the same way, each independent variable occurs at least once in each line (e.g., either under data headings E-LVL or E-LVL-MIN, E-LVL-MAX, see example following). Supplementary information, such as resolution or standard values, is not given on a line of a data table unless the line includes data information. Blanks are permitted in all fields. An example of a point data table is shown below with its associated DATA and ENDDATA records.
Appendix: Information Identifier KeywordsThis appendix provides a listing of all information-identifier keywords, along with details about their use. The keywords appear in alphabetical order. ADD-RES. Gives information about any additional results obtained in the experiment, but which are not compiled in the data tables. Codes are given in Dictionary 20.
ANALYSIS. Gives information as to how the experimental results have been analyzed to obtain the values given under the heading DATA which actually represent the results of the analysis. Codes are found in Dictionary 23.
ASSUMED Gives information about values assumed in the analysis of the data, and about COMMON or DATA fields headed by ASSUM or its derivatives. The format of the code is: (heading,reaction,quantity) Heading field: data heading to be defined. Reaction field and quantity field: coded as under the keyword REACTION.
AUTHOR. Gives the authors of the work reported.
COMMENT. Gives pertinent information which cannot logically be entered under any other of the keywords available. CORRECTION. Gives information about corrections applied to the data in order to obtain the values given under DATA. See also LEXFOR, Correction. COVARIANCE. Gives covariance information provided by the experimentalist, or to flag the existence of a covariance data file. See Appendix D for covariance file format.
CRITIQUE. Gives comments on the quality of the data presented in the data table. DECAY-DATA. Gives the decay data for any nuclide occurring in the reaction measured as assumed or measured by the author for obtaining the data given . The general format of the coding string consists of three major fields which may be preceded by a decay flag: ((decay flag)nuclide,half-life,radiation). Flag. A fixed-point number that also appears in the data section under the data heading DECAY-FLAG. If the flag may be omitted, its parentheses are also omitted. Nuclide field. A nuclide code. Half-life field. The half-life of the nuclide specified, coded as a floating-point number, followed by a unit code with the dimensions of TIME. Radiation field. Consists of three subfields: (type of radiation, energy, abundance). This field may be omitted, or repeated (each radiation field being separated by a comma). The absence of any subfield is indicated by a comma; trailing commas are not included. SF1. Type-of-radiation. A code from Dictionary 13. Where two or more different decay modes are possible and are not distinguished in the measurement, two or more codes are given; each separated by a slash. (See Example b, following). SF2. Energy. The energy of the radiation in keV, coded as a floating-point number. In the case of two or more unresolved decays, two or more energies, or a lower and upper energy limit, are given, each separated by a slash. (See Example e). SF3. Abundance. The abundance of the observed per decay, coded as a floating-point number.
DECAY-MON. Gives the decay data assumed by the author for any nuclide occurring in the monitor reaction used. The coding rules are the same as those for DECAY-DATA, except that there is no flag field. DETECTOR. Gives information about the detector(s) used in the experiment. Codes are found in Dictionary 22. If the code COINC is used, then the codes for the detectors used in coincidence follow within the same parenthesis;
EMS-SEC. Gives information about secondary squared effective mass of a particle or particle system, and to define secondary-mass fields given in the data table. The format of the coded information is: (heading, particle). Heading Field contains the data heading or the root of the data heading to be defined. Particle Field contains the particle or nuclide to which the data heading refers. The code is: either a particle code from Dictionary 13. or a nuclide code.
EN-SEC. Gives information about secondary energies, and to define secondary-energy fields given in the data table. The format of the coded information is: (heading,particle). Heading Field. Contains the data heading or the root of the data heading to be defined. Particle Field. Contains the particle or nuclide to which the data heading refers. The code is: either a particle code from Dictionary 13. or a nuclide code.
ERR-ANALYS. Explains the sources of uncertainties and the values given in the COMMON or DATA sections under data headings of the type ERR- or -ERR. The general code format is (heading,correlation factor) free text. Heading Field. Contains the data heading or the root of the data heading to be defined. Correlation Factor Field contains the correlation factor, coded as a floating point number.
EXP-YEAR. Defines the year in which the experiment was performed when it differs significantly from the data of the references given (e.g., classified data published years later).
FACILITY. Defines the main apparatus used in the experiment. The facility code from Dictionary 18 may be followed by an institute code from Dictionary 3, which specifies the location of the facility.
FLAG. Provides information to specific lines in a data table. See also LEXFOR, Flags.
HALF-LIFE. Gives information about half-life values and defines half-life fields given in the data table. The general coding format is: (heading,nuclide)
HISTORY. Documents the handling of an entry or subentry. The general format of the code is: (yyyymmddX), where yyyymmdd is the date (year,month,day) and X is a code from Dictionary 15.
INC-SOURCE. Gives information on the source of the incident particle beam used in the experiment. Codes are found in Dictionary 19.
INC-SPECT. Provides free text information on the characteristics and resolution of the incident-projectile beam. INSTITUTE. Designates the laboratory, institute, or university at which the experiment was performed, or with which the authors are affiliated. Codes are given in Dictionary 3.
LEVEL-PROP. Gives information on the spin and parity of excited states. The general format of the code is ((flag) nuclide, level identification, lever properties) Flag. Coded as a fixed-point number that appears in the data section under the data heading LVL-FLAG. when the flag is omitted, its parentheses are also omitted. Nuclide. Coded is a nuclide, except that the use of the extension G is optional. Level identification. Identification of the level whose properties are specified, given as either a level energy or level number. If the field omitted, its separating comma is omitted. Level Energy. The field identifier E-LVL= followed by the excited state energy in MeV, coded as a floating-point number which also appears in the data section under the data heading E-LVL. Level Number. The field identifier LVL-NUMB= followed by the level number of the excited state, coded as a fixed-point number which also appears in the data section under the data heading LVL-NUMB. Level properties. Properties for the excited state, each preceded by a subfield identification. At least one of the fields must be present. If the field is omitted, its separating comma is omitted. Spin. The field identifier SPIN=, followed by the level spin coded as a floating point number. For an uncertain spin assignment, two or more spins may be given, each separated by a slash. Parity. The field identifier PARITY=, followed by the level parity, coded as e.g., +1. or -1.
METHOD. Describes the experimental technique(s) employed in the experiment. Codes are found in Dictionary 21.
MISC-COL. Defines fields in the COMMON or DATA sections headed by MISC and it derivatives.
MOM-SEC. Gives information about secondary linear momentum, and defines secondary-momentum fields given in the data table. The general code format is: (heading,particle) Heading Field: the data heading or root of the data heading to be defined. Particle Field: the particle or nuclide to which the data heading refers. The code is: either a particle code from Dictionary 13. or a nuclide code.
MONITOR. Gives information about the standard reference data (standard, monitor) used in the experiment and defines information coded in the COMMON and DATA sections under the data heading MONIT, etc. The general coding format is ((heading) reaction) Heading Field. Contains the data heading of the field in which the monitor value is given. If the heading is omitted, its parenthesis is omitted. Reaction Field. The coding rules are identical to those for REACTION, except that subfields 5 to 9 may be omitted if the reaction is known.
MONIT-REF. Gives information about the source reference for the standard (or monitor) data used in the experiment. The general code format is ((heading)subaccession#,author,reference) Heading Field: Data heading of the field in which the standard value is given. If the heading is omitted, its parentheses are also omitted. Subaccession Number Field: Subaccession number for the monitor data, if the data is given in an EXFOR entry. Cnnnn001 refers to the entire entry; Cnnnn000 refers to a yet unknown subentry. Author Field: The first author, followed by "+" when more than one author exists. Reference Field: May contain up to 6 subfields, coded as under REFERENCE.
PART-DET. Gives information about the particles detected directly in the experiment. Particles detected in a standard/monitor reaction are not coded under this keyword. The code is either a code from Dictionary 13, or, for particles heavier than a particles, a nuclide code. Particles detected pertaining to different reaction units within a reaction combination are coded on separate records in the same order as the corresponding reaction units.
RAD-DET. Gives information about the decay radiations (or particles) and nuclides observed in the reaction measured. The general format of the code is ((flag)nuclide, radiation). Flag is a fixed-point number which appears in the data section under the data heading DECAY-FLAG. If the field is omitted, its parentheses are also omitted. Nuclide contains a nuclide code. Radiation contains one or more codes from Dictionary 33, each separated by a comma.
REACTION. Specifies the data presented in the DATA section in fields headed by DATA. The general format of the code is (reaction, quantity, data-type). Reaction field. The reaction field consists of 4 subfields. SF1. Target nucleus. Contains either:
SF2. Incident projectile. Contains one of the following:
SF3. Process. Contains one of the following:
If SF5 contains the branch code UND (undefined), the particle codes given in SF3 represent only the sum of emitted nucleons, implying that the product nucleus coded in SF4 has been formed via different reaction channels. The code (DEF) in SF5 denotes that it is not evident from the publication whether the reaction channel is undefined or defined. SF4. Reaction Product. In general, the heaviest of the products is defined as the reaction product (also called residual nucleus). In the case of two reaction products with equal mass, the one with the larger Z is considered as the heavier product. Exceptions or special cases are:
Quantity consists of four subfields, each separated by a comma. All combinations of codes allowed in the quantity field are given in Dictionary 36. SF5 Branch. Indicates a partial reaction, e.g., to one of several energy levels. SF6 Parameter. Indicates the reaction parameter given, e.g., differential cross section. SF7 Particle Considered. Indicates to which of several outgoing particles the quantity refers. Multiple codes, e.g., for the correlation between outgoing particles, all particles are separated by a slash. SF8 Modifier. Contains information on the representation of the data, e.g., relative data. Data Type Field. Indicates whether the data are experimental, theoretical, evaluated, etc. Codes are found in Dictionary 35. SF9 Data Type. Variable Nucleus. For certain processes, the data table may contain yield or production cross sections for several nuclei which are entered as variables in the data table. In this case, either SF1 or SF4 of the REACTION keyword contain one of the following codes:
The nuclei are entered in the common data or data table as variables under the data headings ELEMENT and/or MASS with the units NO-DIM. If the data headings ELEMENT and MASS are used, a third field with the data heading ISOMER is used when isomer states are specified:
Decay data for each entry under ELEMENT/MASS(ISOMER) and their related parent or daughter nuclides may be given in the usual way under the information-identifier keyword DECAY-DATA. Entries under the data headings ELEMENT/MASS(ISOMER) are linked to entries under DECAY-DATA (and RAD-DET, if present) by means of a decay flag.
Variable Number of Emitted Nucleons. Where mass and element distributions of product nuclei have been measured, the sum of outgoing neutrons and protons may be entered as variables in the data table. In this case SF3 of the REACTION keyword contains at least one of the following codes:
The numerical values of the multiplicity factors X and Y are entered in the data table under the data headings N-OUT and P-OUT, respectively.
Reaction Combinations. For experimental data sets referring to complex combinations of materials and reactions, the code units defined in this section can be connected into a single machine-retrievable field, with appropriate separators and properly balanced parentheses. The complete reaction combination is enclosed in parentheses.
When a reaction combination contains the separator "//", the data table will contain at least one independent variable pair with the data heading extensions -NM and -DN.
REFERENCE. Gives information on references that contain information about the data coded. Other related references are not coded under this keyword (see REL-REF, MONIT-REF). The general coding format is (reference type, reference, date). The format of the reference field is dependent on the reference type. The general format for each reference type follows.
Type of Reference = B or C; Books and Conferences.
Type of Reference = J: Journals.
Type of Reference = P or R or S; Reports.
Type of Reference = T, or W; Thesis or Private Communication.
REL-REF. Gives information on references related to, but not directly pertaining to, the work coded. The general code format is: (code,subaccession#,author,reference). Code: code from Dictionary 17. Subaccession #: EXFOR subaccession number for the reference given, if it exists. Cnnnn001 refers to the entire entry Cnnnn. Cnnnn000 refers to a yet unassigned subentry within the entry Cnnnn. Author: first author, coded as under AUTHOR, followed by + when more than one author exists. Reference: coded as for REFERENCE.
RESULT. Describes commonly used quantities that are coded as REACTION combinations.
SAMPLE. Used to give information on the structure, composition, shape, etc., of the measurement sample. STATUS. Givews information on the status of the data presented. Entered in one of the general code formats, or for cross reference to another data set, the general code format is: (code,subaccession#) Code: code from Dictionary 16. Subaccession# Field: cross-reference to an EXFOR subaccession number, see REL-REF.
TITLE. Gives the title for the work referenced. [ Online Services | Partners | About | Team | Publications | Contacts
If you have any questions, comments, and/or suggestions, please, contact ©Webdesign by nnp, 2000. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||