Стандартный идентификатор нуклида состоит из 2-х частей - массового числа в позициях 1-3, выровненного по правому краю, и химического символа элемента (или Z-100 для Z > 109) в позициях 4-5, выровненного по левому краю. Идентификатор нуклида должен располагаться в поле, отведённом для него (позиции 1-5). Идентификатор нуклида обязан быть в каждой записи набора данных кроме записи END. Комментарии и ссылки набора данных, относящегося ко всей массовой цепочке содержат только значение массового числа в поле NUCID.
Идентификатор набора данных ID наборов данных ENSDF должен обеспечивать уникальную компьютерно-распознаваемую идентификацию набора данных. Не может быть двух наборов данных с идентичными DSID и NUCID. В редких случаях два набора данных должны иметь идентичные DSID и NUCID; в этом случае DSID дополняется (в конце) символом ':' (двоеточие) с последующим уникальным идентификатором, позволяющим различать такие наборы друг от друга.
В этих целях должны строго исполняться следующие правила. Одиночные пробелы являются значимыми и должны использоваться согласно нижеописанным форматам. Ниже необязательные поля даются курсивом. Общие понятия даются в верхнем и нижнем регистрах и определяются ниже. Все DSID должны дополняться до 30 символов пробелами. Это поле при необходимости может быть продолжено на поле DSID на последующих записях продолжения, как это описано в главе 3. В этом случае DSID на первой записи должен заканчиваться символом ',' (запятая).
GENERAL ID'S
REFERENCES
COMMENTS (смотрите формат этого набора данных в приложении B)
ADOPTED LEVELS
ADOPTED LEVELS, GAMMAS
Реально существует идентификатор:
HIGH-SPIN LEVELS, GAMMAS
описания которого переводчик не смог найти, но наборы с этим
идентификатором аналогичны наборам с идентификатором
ADOPTED LEVELS, GAMMAS
(Этот идентификатор устарел и остался только в старых наборах данных.
Примечание J.K.Tuli.)
DECAY DATA SET ID'S
Parent Mode Decay (Half-life)
| Parent | должен быть символом родительского изотопа (например, 52CR). Для спонтанного деления может приводиться более одного родительского изотопа (через запятую). Для распада ионизированного атома после символа родительского изотопа в квадратных скобках приводится ионизационное состояние: 187RE[+75]. |
| Mode | может быть одним из B+, B-, EC, IT, A, P, B-N, ECP, SF,... Список распадных мод может расширяться. |
| Half-life | может быть в форме T, описанной в V.14.1. |
MUONIC ATOM
REACTION DATA SET ID'S
Target(Reaction), (Reaction), Target(Reaction) E=Energy Qualifier
COULOMB EXCITATION
INELASTIC SCATTERING
(Устарел. Встречается только в старых наборах данных. Примечание J.K.Tuli.)
(HI,XNG)
Target должна быть символом мишени (изотоп или элемент)
Reaction должна быть символом реакции в виде (in,out), например (N,P),
где in - налетающая частица, out - улетающая частица.
Energy должна быть одного из следующих видов
число, число единица (определение числа приведено в V.9)
число-число единица
THERMAL или TH (для тепловых)
RESONANCE или RES (для резонансных)
Qualifier должен быть одного из следующих видов
RES
IAR
IAS
Примеры:
187RE B- DECAY 187OS IT DECAY (231 US)
187RE[+75] B- DECAY 187AU P DECAY:?
190PT A DECAY (6E11 Y) 95RB B-N DECAY
186OS(N,G) E=THERMAL 186W(N,G) E=TH: SECONDARY G'S
RE(N,N'):TOF 186W(N,G) E=RES: AVG
189OS(P,T) E=19 MEV 187OS(D,D') E=12, 17 MEV
185RE(A,2NG) E=23-42.8 MEV 187RE(D,2NG), 187RE(P,NG)
44CA(P,G) E=856, 906 KEV IAR 238U(N,FG) E=TH
PB(238U,FXG) PB(238U,XG)
Данное поле используется в записях IDENTIFICATION и CROSS-REFERENCE.
Поля DSREF и QREF могут
включать до 3-х ключевых слов (по формату NSR) - KEYNUM,
каждое из которых является ссылкой на отдельную публикацию.
Добавочные ключевые слова могут помещаться в записи
COMMENT.
Ключевые слова должны прижиматься к левому краю и разделяться запятыми
без пробелов между запятыми и ключевыми словами.
Ключевое слово ссылки должно иметь форму YYYYAABB, где
YYYY - целое из четырёх цифр,
AA - 2 буквы латинского алфавита, и BB - 2 цифры
или 2 буквы латинского алфавита. Примеры:
1981TU01, 1981TUXY, и так далее.
В связи с размером поля QREF в нем могут размещаться только до 2-х ключевых слов (KEYNUM); упоминание о трёх - дань истории. До 2000 года ключевое слово было на два символа короче (примечание переводчика).
Данные поля используются в записях IDENTIFICATION, Q-VALUE и REFERENCE.
Информация о публикации состоит из года публикации массовой цепочки в Nuclear Data Sheets, обозначенного 2-мя последними цифрами года и буквами NDS для Nuclear Data Sheets или буквами NP для Nuclear Physics-A. За ней может следовать запятая и другая информация о модификации, например, инициалы человека, модифицировавшего набор после этой публикации. Примеры: 78NDS,TWB или 81NDS.
Кроме указанных форматов зачастую используется слово ENSDF, с возможными 2-мя последними цифрами года - по-видимому должно означать, что включено в ENSDF, но ещё не опубликовано (примечание переводчика).
Данное поле используется только в записи IDENTIFICATION.
Это поле имеет форму YYYYMM, где
YYYY - целое из 4-х цифр,
![]() 1900
1900![]() MM
MM![]() 12.
12.
Данное поле используется только в записи IDENTIFICATION.
RTYPE - это двухсимвольный код в позициях 8-9, который определяет тип записи (в большинстве случаев в позиции 9 находится пробел).
| RTYPE | Описание |
|---|---|
| пусто | Может быть в записях IDENTIFICATION, общий COMMENT или END. |
| H | Запись HISTORY. |
| N | Запись NORMALIZATION. Запись PRODUCTION NORMALIZATION в позиции 7 содержит символ 'P'. |
| P | Запись PARENT. |
| Q | Запись Q-VALUE. |
| L | Запись LEVEL. |
| G | Запись GAMMA. |
| B | Запись BETA ( |
| E | Запись EC ( |
| A | Запись ALPHA. |
| R | Запись REFERENCE. |
| X | Запись CROSS-REFERENCE. |
| DP | Запись DELAYED PARTICLE, или PARTICLE, если в позиции 8 - пробел; в позиции 9 - символ частицы (например, "P" - для протона). |
Данное поле используется во всех записях согласно данному описанию.
Это поле имеет свободный формат. Различные выражения, используемые в этом поле, могут быть преобразованы согласно словарю преобразования символов. Словарь приведён в приложении F. Выражением, подлежащим преобразованию, является строка символов, заключённая в "ограничители", в-притирку. В настоящее время используются следующие "ограничители":
пробел, запятая, точка с последующим пробелом и следующие символы:
; : ( ) - = + < > / $
В некоторых случаях программы преобразования делают предварительный просмотр за ограничителем, для правильного преобразования.
Данное поле используется в записях Общий комментарий (General Comments), Комментарии к записям (Record Comments) и Комментарии сносок (Footnote Comments).
Поле SYM(FLAG) (с данным FLAG) допустимо только в записях с RTYPE: L, G, B, E, A, DP. Однако SYM (без FLAG) может также использоваться в записях типа N, P и Q.
FLAG может быть строкой символов, выделенной (необязательно) запятыми. Любой символ, отличный от запятой и круглых скобок, может использоваться в строке FLAG. Для записей B и E символ 'C' не может использоваться как FLAG, так как сам символ 'C' в позиции 77 записей B, E и A означает "совпадения". Аналогично, символы '*', '@', '%' и '&' в записи G резервируются для специальных целей (III.B.14). Смотрите замечание по SYM и FLAG в COMMENT (III.B.5). Также отметим, что FLAG может использоваться только с BAND и CONF вдобавок к тем SYM'ам, которые являются допустимыми на форматированных картах. Фактически для BAND FLAG должен быть дан.
Символы, допустимые для использования в SYM в различных RTYPE в настоящее время ограничиваются полями, допустимыми в этих записях.
Эти поля либо заполняются пробелами, либо одним беззнаковым числом (NUM) в одной из следующих форм:
Замечание: желательно писать число как '0.345', а не '.345'. Тем не менее, даже если ведущий нуль опущен (например, для экономии позиций), в Nuclear Data Sheets число будет с ведущим нулём (примечание переводчика).
Данное поле используется в записях PARENT, NORMALIZATION, PRODUCTION NORMALIZATION, BETA, EC, ALPHA и GAMMA.
В этих полях для представления чисел используется та же форма, как для величин, описанные выше, в пункте V.9, с тем отличием, что у этих величин допустим знак (плюс или минус).
Данное поле используется в записях Q-VALUE и GAMMA.
Эти двухсимвольные поля, представляющие
погрешность значения соответствующих им полей в "стандартной" форме.
"Стандартная" числовая погрешность означает погрешность
в единицах последнего знака, например, NR=0.873, DNR=11 означает фактор
нормализации ![]() 0.011,
0.011,![]() 1.0)*106
1.0)*106![]() и тому подобных, употребляются выражения LT, GT, GE и т.д.
и тому подобных, употребляются выражения LT, GT, GE и т.д.
Величина DNB должна быть двухсимвольной, хотя и занимает 6-символьное поле (см. запись NORMALIZATION, III.7, Замечания).
Допустимые формы этих полей перечислены ниже.
| 1. | Пробел |
| 2. | Целое, меньшее 100, желательно не более 25 (прижатые к левому или правому краю поля) |
| 3. |
Одно из следующих выражений: |
Данное поле используется в записях Q-VALUE, PARENT, NORMALIZATION, PRODUCTION NORMALIZATION, LEVEL, BETA, EC, ALPHA, (DELAYED-)PARTICLE и GAMMA.
Эти поля допускают указание
"стандартной" несимметричной погрешности.
Например, T=4.2 S DT=+8-10, означает период
полураспада ![]() секунды, аналогично, MR=-3 DMR=+1-4 означает коэффициент смешивания
секунды, аналогично, MR=-3 DMR=+1-4 означает коэффициент смешивания
![]() ,
,![]() не помещается в пределах поля, то цифры или выражения в этом поле
представляются либо "стандартной" симметричной погрешностью,
либо нечисловой погрешностью, как описано выше в пункте
V.11.
не помещается в пределах поля, то цифры или выражения в этом поле
представляются либо "стандартной" симметричной погрешностью,
либо нечисловой погрешностью, как описано выше в пункте
V.11.
Таким образом, возможны 2 случая:
Данное поле используется в записях PARENT, NORMALIZATION, LEVEL, BETA, EC, ALPHA, (DELAYED-)PARTICLE и GAMMA.
В этих полях допустимы следующие числа/выражения:
Замечание: круглые скобки означают, что число является выведенным, а не измеренным, или получено из другого(их) эксперимента(ов).
Данное поле используется в записях BETA, EC, ALPHA, (DELAYED-)PARTICLE и GAMMA.
Это поле представляет собой период полураспада и может иметь одну из перечисленных форм:
Для единиц измерения допустимы следующие символы:
Y, D, H, M, S, MS, US, NS, PS, FS, AS, EV, KEV и MEV,
что означает: год, день, час, минута, секунда, миллисекунда,
микросекунда, наносекунда, пикосекунда, фемтосекунда,
аттосекунда, электрон-Вольт, килоэлектрон-Вольт
и мегаэлектрон-Вольт.
Замечание: символ '?' за периодом полураспада означает, что значение не является надёжно установленным. Должен быть дан комментарий для точного объяснения причины.
Данное поле используется в записях PARENT, LEVEL и (DELAYED-)PARTICLE.
Это односимвольное поле, которое может содержать либо пробел, либо символ 'C', либо символ '?'. Символ 'C' означает совпадение, символ '?' означает совпадение под вопросом.
Данное поле используется в записях (DELAYED-)PARTICLE и GAMMA.
Это двухсимвольное поле может быть либо пустым для разрешённых переходов, либо цифрой от 1 до 9, указывающей порядок запрета, с последующим пробелом для неуникального перехода или с символом 'U' для уникального перехода.
Данное поле используется в записях BETA и EC.
Это двухсимвольное поле может быть либо пустым, либо содержать символ 'M', с последующим пробелом или цифрой от 1 до 9.
Данное поле используется только в записи LEVEL.
Поле значения энергии может иметь один из следующих форматов:
Замечание: допустимо значение заключать в круглые скобки. Это означает, что данное значение было выведено (а не прямо измерено) или получено из другого(их) эксперимента(ов). Должно быть приведено объяснение этого факта.
Данное поле используется в записях PARENT, LEVEL, BETA, EC, ALPHA, (DELAYED-)PARTICLE и GAMMA.
Поле мультипольности может иметь один из следующих форматов:
где Mult = EL или ML' (где L, L' - цифрыL 0,
L' или ML'+EL или EL+ML' или D или Q
Замечание: Мультипольность, заключённая в круглые скобки, означает, что назначение вероятно и не определено. Квадратные скобки указывают на подразумеваемое или выведенное значение.
Данное поле используется только в записи GAMMA.
Поле спина-чётности может иметь только один из перечисленных форматов:
1. JPI (может быть J, 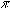 , или
, или J)
2. JPI OR JPI (вместо OR может использоваться запятая)
3. JPI AND JPI (вместо AND может использоваться символ амперсанда '&')
4. OP JPI (где OP - это AP, LE, GE)
Замечание: такая запись интерпретируется как =PI,
а J - OP J. Пример: LE 5+ означает =+ и J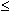 5
5
5. NOT JPI
6. JPI TO JPI (вместо TO может использоваться двоеточие ':')
Замечание: если чётность даётся в диапазоне, то это
интерпретируется так:
(a) J TO J'PI означает JJJ' и =PI
(b) JPI TO J'PI' означает JPI,J=J+1 PI=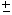 ,...,J=J'-1 PI=,J'PI'
(c) JPI TO J' означает JPI,J=J+1 PI=,...,J=J'-1 PI= J'PI=
Примеры:
(a) 3 TO 6- означает J=3-,4-,5-,6-
(b) 3+ TO 6- означает J=3+,4,5,6-
(c) 3+ TO 6 означает J=3+,4,5,6
7. NATURAL/UNNATURAL
В комбинациях спина и чётности: 0+, 1-, 2+, 3- и т.д. чётность называется
натуральной, в комбинациях 0-, 1+, 2-, 3+ и т.д. - ненатуральной.
8. A или A+JPI (где A - один из символов J, K, L, M, N, O, P,...)
Выше J = N или N/2 (N - целое положительное или 0)
PI() = + или -
JPI = J или PI или J с последующим PI.
,...,J=J'-1 PI=,J'PI'
(c) JPI TO J' означает JPI,J=J+1 PI=,...,J=J'-1 PI= J'PI=
Примеры:
(a) 3 TO 6- означает J=3-,4-,5-,6-
(b) 3+ TO 6- означает J=3+,4,5,6-
(c) 3+ TO 6 означает J=3+,4,5,6
7. NATURAL/UNNATURAL
В комбинациях спина и чётности: 0+, 1-, 2+, 3- и т.д. чётность называется
натуральной, в комбинациях 0-, 1+, 2-, 3+ и т.д. - ненатуральной.
8. A или A+JPI (где A - один из символов J, K, L, M, N, O, P,...)
Выше J = N или N/2 (N - целое положительное или 0)
PI() = + или -
JPI = J или PI или J с последующим PI.
Замечания:
Круглые скобки в поле J![]() указывают, что значение, заключённое в круглые скобки, основано на
слабой аргументации, см. "Основания для
назначения спина и чётности".
Отметим, что JPI=(3,4)- интерпретируется как J=(3) или (4),
а
указывают, что значение, заключённое в круглые скобки, основано на
слабой аргументации, см. "Основания для
назначения спина и чётности".
Отметим, что JPI=(3,4)- интерпретируется как J=(3) или (4),
а ![]() =-.
=-.
По возможности даётся не более трёх значений JPI.
Диапазоны типа 3- ... 5+ лучше записывать в виде 3-,4,5+.
Квадратные скобки вокруг значения J![]() указывают на подразумеваемое значение.
указывают на подразумеваемое значение.
Данное поле используется в записях PARENT и LEVEL.
Это поле может содержать не более чем три S-значения в форме NUM (определённое выше в пункте V.9), разделённые символами '+' или запятыми для соответствующих L-значений, данных в поле L (позиции 56-64). Допускается использование круглых скобок для указания того, что эти значения являются вероятными.
Данное поле используется только в записи LEVEL.
Это поле может содержать не более трёх целых чисел (с возможно предшествующими LE или GE), разделяемых символами '+' или запятыми. Значения могут заключаться в круглые скобки, что интерпретируется как вероятные значения. Квадратные скобки указывают на подразумеваемые или выведенные значения.
В некоторых реакциях значение L может сопровождаться спецификацией электрического или магнитного характера в форме, подобной записи мультипольности (смотрите пункт V.19).
Данное поле используется в записях LEVEL и (DELAYED-)PARTICLE.
Это поле либо пустое, либо знаковое целое, прижатое к левому краю, и обозначающее степень ионизации атома, пример: +75. Это поле используется в наборах данных распада ионизированных атомов (Ionized Atom Decay) в записях PARENT.
Перекрёстные ссылки для записи (в настоящее время допустимые только для L-записи в ОЦЕНЁННЫХ наборах данных) производятся посредством записей продолжения и имеют следующие формы:
| 1. | NUCID 2 L XREF=ABC$ |
Такая запись указывает, что оценённых уровень (специфицированный предыдущей L записью) рассматривается в наборах данных "A", "B" и "C", и что соответствующие уровни считаются несомненно существующими. |
|
| 2. | NUCID 2 L XREF=A(E1)B(E2)C(E3)$ |
Такая запись указывает, что принятый уровень тот-же, что и уровень E1 в наборе данных "A", уровень E2 в наборе данных "B", и так далее. |
|
| 3. | NUCID 2 L XREF=A(E1,E2)B(E3)$ |
Такая запись указывает, что принятый уровень или E1 или E2 в наборе данных "A", уровень E3 - в наборе данных "B". |
|
| 4. | NUCID 2 L XREF=A(*E1)B(E2)$ |
Такая запись указывает, что уровень с энергией E1 в наборе данных "A" ассоциируется с более чем одним принятым уровнем. Символ '*' должен появляться во всех случаях множественного назначения уровня. Альтернативно, запись A(*) может использоваться, если энергия очевидна. |
|
| 5. | NUCID 2 L XREF=+$ |
Такая запись указывает, что принятый уровень виден во всех наборах данных. |
|
| 6. | NUCID 2 L XREF=-(AB)$ |
Такая запись указывает, что принятый уровень виден во всех наборах данных, кроме "A" и "B". |
Замечание: Символы A, B и C, относящиеся к отдельным наборам данных, должны быть определены при помощи записей перекрёстных ссылок (смотрите пункт III.B.4).
| 1. | Во всех индивидуальных наборах данных в ENSDF (за исключением наборов REFERENCE и COMMENTS) предполагается наличие следующей информации (если какое-либо поле не помечено как необязательное, то оно должно присутствовать) в записи H, изменяющейся при каждом обновлении набора данных (см. описание H записи в III.B.2).
| ||||||||||||
| 2. | Текущий список значений TYP (впоследствии может расширяться)
| ||||||||||||
| 3. | Даты должны приводиться в формате DD-MMM-YYYY (например, 31-MAY-1996). | ||||||||||||
| 4. | Ссылка на публикацию (необязательная) даёт информацию о публикации данной оценки. CIT=ENSDF означает, что набор включён в ENSDF, но ещё не опубликован. | ||||||||||||
| 5. | Комментарий (необязательный) может давать общие замечания об оценке/модификации набора данных. | ||||||||||||
| 6. | В записи H поля могут быть в произвольном порядке. |
Отметим, что записи об истории указывают на различные ревизии набора данных. При следующей полной (FUL) оценке они удаляются, и история пишется заново.
Для полной оценки (FUL) в NNDC запись History будет формироваться на основе набора данных COMMENTS.
Примеры:
156DY H TYP=MOD$AUT=B. Singh$DAT=31-DEC-1995$ 156DY2H COM=Updated SDB data only$ 156DY H TYP=UPD$AUT=R. Helmer$CUT=15-DEC-1994$ 156DY2H COM=Updated data set since last full evaluation$ 156DY H TYP=FMT$AUT=J. Tuli$DAT=1-DEC-1994$COM=FIXED T1/2$ 156DY H TYP=FUL$AUT=R. Helmer$CUT=01-May-1991$ 156DY2H CIT=NDS 65, 65 (1992)$